分布式键值存储(Distributed Key-Value Store)
前言
分布式键值存储(Distributed Key-Value Store)并不是一个新鲜的玩意。
常见的Redis,Memcache等等都有很多人在用。
不过如果要是说其中的细节,如replicate,读写,一致性,retry等等的话,又是经常会遇到把自己绕的混淆不清的情况。。
恰巧我最近在看的一门网课《Programming Reactive Systems》中有一道作业题就是要自己实现一个Distributed Key-Value Store,那就正好借此机会详细写下其中的关键点。
组成系统的参与者
既然是分布式键值存储,那么肯定会有主从节点,每个结点又会有自己的持久化,而主从之间也需要协调,于是就得出了如下关键参与者:
- Primary: 主节点。接受来自client的更新(增/删/改)操作,并把更新后的数据扩散到其它节点。当然,也可以接受来自于client的读操作。
- Secondary: 从节点。接受来自主节点的更新操作。接受来自client的只读操作。
- Arbiter: 仲裁者。任何节点,无论主从,都要把自己注册到Arbiter上去。当有从节点加入或者离开集群的时候,Arbiter负责告知主节点。
- Persistence: 每个节点都拥有自己的独享的Persistence。用于把节点上的数据持久化。
- Clients: 客户端,可能与主或者从节点通信,进行各种读写操作。
此外,还有另一个相对不那么关键的参与者:
- Replicator: 复制器,负责扩散数据。主节点和从节点之间的桥梁。主节点扩散到从节点去的数据要经手Replicator。
之所以需要它是为了把一部分维护内部状态的职责从Primary身上解除出去,具体来说是一个sequence number序列号,后面会提到。
参与者之间的关系
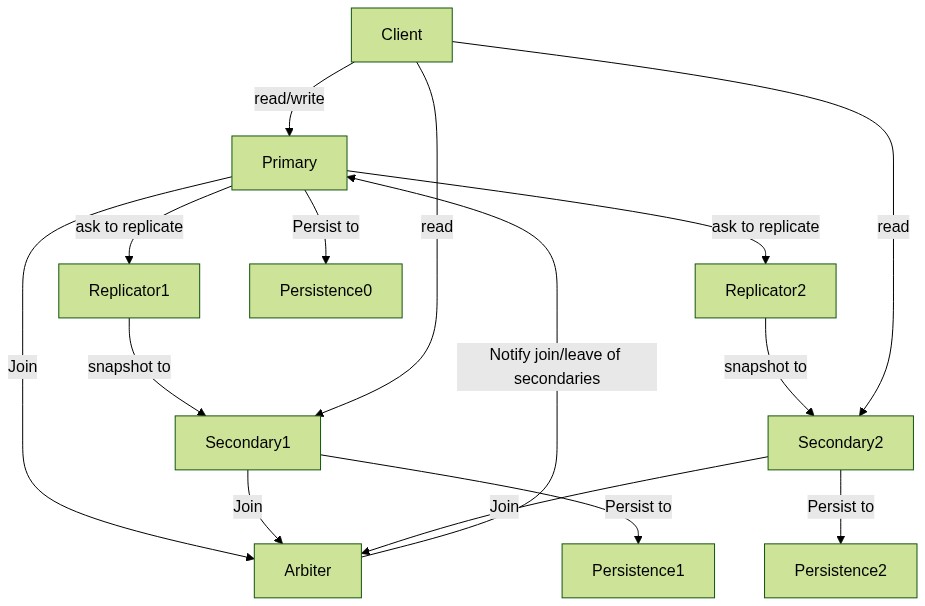
可以看出,系统中有一个Primary,多个Secondary(虽然图中只画了两个,但是理论上可以有任意N多个)。
Primary向Secondary扩散数据是通过Replicator进行的,并且是给每个Secondary配了一个单独的Replicator。
也就是说Replicator和Secondary是成双成对的。
注:上图描述的是各个参与者之间的关系,上下左右位置并不代表先后顺序
一些限制
我们并不是要做一个可以在Prod环境中使用的KV Store,而只是借助自己实现来厘清KV Store的一些知识点,所以做出了如下的限制来简化实现:
- 只有主节点可以接受写操作,所有从节点都只能接受读操作
- 假设主节点是稳定可靠的,不会挂(不处理主节点身份转移)
- 假设Arbiter是可靠的,不会挂
- 不处理背压(back pressure)
- 客户端使用的请求id是不会重复的
各参与者的职责及相互之间的交互
以下的这些图,每一张都只关心系统中的一个局部。主要原因在于把整个系统的交互放到一张图里会导致要素太多而难以阅读。
Arbiter

来的早的会被Arbiter当作Primary,来的晚的就是Secondary了。
并且,每一个来的晚的成为Secondary之后,Arbiter还会告知Primary说:来新节点了。以便Primary可以知道后续需要把数据扩散给谁。
如果有Secondary由于某种原因而离开了集群,Arbiter也会告知Primary,从而避免Primary继续给已经不在了的Secondary发消息。
Persistence

前面提到过,每个节点,无论主从,都有一个自己独享的persistence。所以上图中的Node兼指主或者从节点。
Persistence本身的职责很简单,把Node告诉它的数据持久化下来。
但是,此处我们并没有假设持久化总是可靠的,所以上图中的第二根线是未必总是能成功发生的。
Node

这里的Node兼指主或者从节点。也就是说上图中的事情是每个Node无论主从都要做的。
每一个Node,在它生命周期的最早开始作的第一件事就是告诉Arbiter:“我来了“。
上面提到过,Persistence未必总是可靠的。所以每个Node一旦开始存活,就会给自己启动一个定时任务,每隔100ms就去retry persist,直到Persitence回话说Persisted为止才停止retry。
Secondary
Secondary - Snapshot
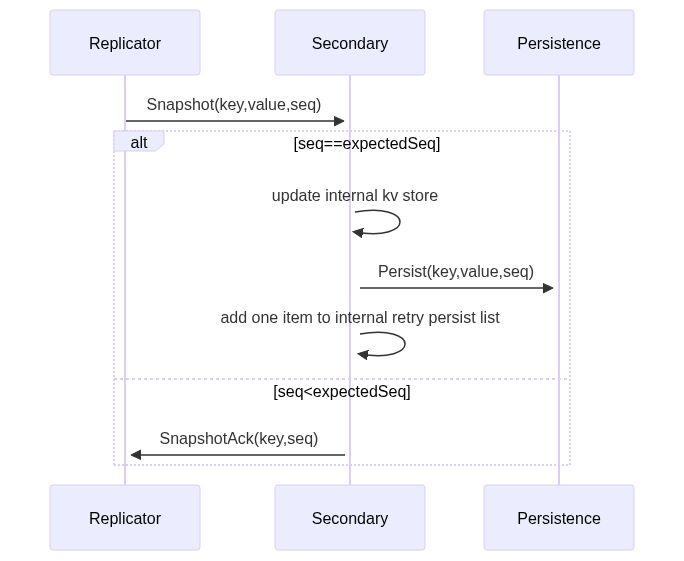
上图描述的是当Replicator向Secondary扩散数据的时候,Secondary如何处理。
一旦一个Replicator告诉Secondary去更新数据(增/删/改),Secondary先去更新自己内部的kv,然后去告知Persistence去做持久化。
这里有一个细节,就是图中出现的seq(sequence number 序列号)。Replicator和Secondary之间就是靠这个seq来保证数据更新操作总是先来的先处理,后来的后处理。
据此来提供一定程度的consistency。避免老数据覆盖新数据(此处需要结合下文中replicator的retry snapshot来理解)。
Secondary - Persisted
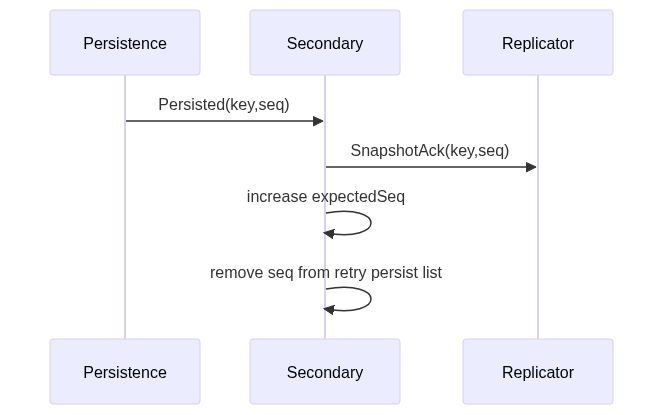
上图描述的是,当Persistence告诉Secondary:“持久化好了“的时候,Secondary如何处理。
可以看出来,只有确认持久化完成之后,Secondary才会告诉Replicator:“扩散数据完成了“,并且在Secondary自己内部取消掉这一条数据的retry persist。
Secondary - Get

对于来自于Client的读取操作,Secondary总是心直口快,有就是有,没有就是没有。
Replicator
Replicator - retry snapshots
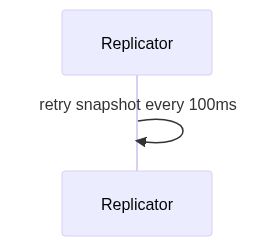
上面提到过,Persistence未必总是可靠的,也就意味着数据扩散操作也未必总是成功,所以,Replicator一旦启动(被Primary创建出来),就要开始一个定时任务来不断retry尚未成功的数据扩散操作。
Replicator - Replicate

上图描述的是当Primary要求Replicator去扩散数据到一个Secondary的时候Replicator如何处理。
那么Replicator首先告诉Secondary去更新数据,然后在自体内部把刚才的操作记下来,以便后续retry。并且把自己的seq加一,这里的seq就是Replicator和Secondary之间的信物,用来维持consistency。
Replicator - SnapshotAck

上图描述的是Replicator在被Secondary告知扩散数据成功后如何处理。
先把这个好消息告诉给Primary,然后在retry的列表里面去除掉刚刚成功的这次操作,这样后面就再也不会再去retry这次操作了。
Primary
最后是Primary。作为主节点,它的职责是最多最辛劳的。
Primary - Insert/Remove

上图是Primary处理来自Client的Insert或者Remove请求。
前面一半和Secondary处理Snapshot方式基本一致。
不同之处就在于:
Primary还要负责告诉所有现存的Replicator(图里只画了两个,理论上可以有任意N个)去扩散数据。并且把这个操作记在内部状态里。
以及设置一个定时任务,一秒钟之后,如果没有达成Primary自己persist成功并且每一个Replicator都扩散成功的状态,那就告诉Client这次操作是失败的。
Primary - Get
至于Primary处理来自于Client的Get请求的图就不画了,与Secondary完全一致。
Primary - Persisted
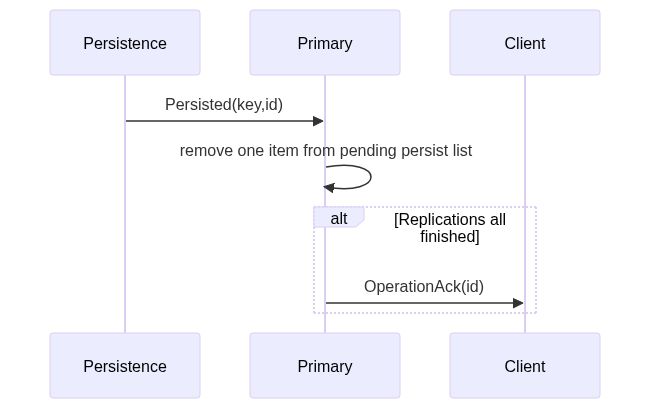
上图是Primary收到Persistence成功消息的时候要做的事情。
首先从pending persist列表中移除刚刚persist成功的一条。
然后检查下是不是所有Replications也都完成了,两个条件的都符合的话,就告诉Client说操作完成了。
Primary - Replicated
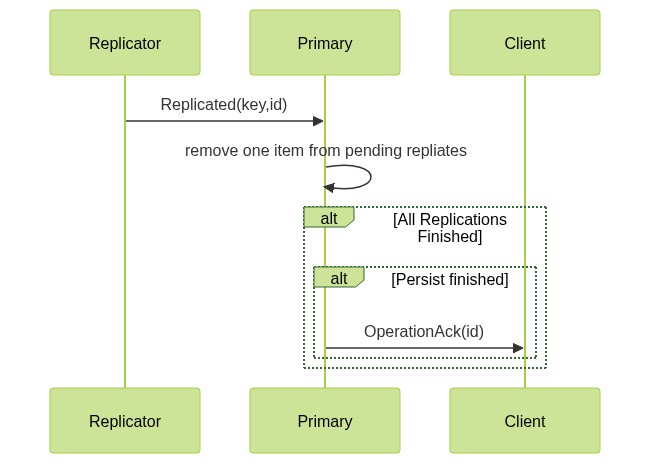
上图是Primary收到来自Replicator的扩散成功消息时候的处理。
首先把刚成功的这一条从pending replicates中移除。
然后检查下是不是所有的replications都完成了(毕竟这里只是收到了一个replicator的消息),并且persist也完成了,如果两条都符合,就告诉Client说操作完成了。
到这里就明显可以看出,pending replicates的作用就是primary用来记录尚未完成的replication。
Primary - Replicas

最后一张图,描述的是当Arbiter告知Primary集群中有变动时,Primary的处理方式。
对于新加入的Secondary,给它们每个都创建一个新的Replicator。然后通过Replicator把所有现存的kv数据都甩给新加入的Secondary。类似于给插班生补课。
对于离开集群的Secondary,把和它们相关的pending replicates都删掉,既然它离开了,那就没必要等它了。删除掉之后马上检查一下是不是replications和persist都完了(因为有可能当前等的就是这个离开的Secondary,它一离开,没有别的需要等的了),如果是的话,那就告诉Client更新成功了。
最后,销毁掉对应的replicator。这个Secondary的历史使命就算终结了。如果后续这个Secondary又加入回来了,那走的就是上面一段补课的处理。
OK
虽然讲的是一个加了若干限制的分布式键值存储,但是还是用了十四张图。
这些图里没能体现到的一点是关于异步的问题,在最后补充一句:
除了Client之外,以上所有提到的参与者,每一个都是严格单线程的,不会在任何时候同时做两件事。
实际的实现代码中,是用akka写的,这些参与者做的多数都是async message passing的工作。
由于这是一门课的作业题,所以具体实现代码就不提及了。
希望这些图表对于理解分布式键值存储(Distributed Key-Value Store)会有一些帮助。